Делаем простое приложение на http4s
Недавно я захотел сделать простенькое демо для своей библиотеки, определяющей схожесть изображений. И заодно попробовать какую-нибудь новую технологию. Так как библиотека написана на скале, мой выбор ограничивался скала фреймворками. С Play и Akka HTTP я уже работал, смысл существования Scalatra мне не особо понятен, а к твиттеровскому стеку душа совершенно не лежит. Поэтому выбор пал на http4s ― свежий и активно развивающийся фреймворк, ориентированный на минимализм и функциональное программирование.
Исходники получившегося проекта выложены на гитхаб.
Начало работы
В документации http4s есть команда для генерации шаблона проекта:
sbt -sbt-version 1.2.1 new http4s/http4s.g8 -b 0.19
0.19 ― это версия фреймворка. Я использовал последнюю на момент написания статьи. Теперь при запуске проекта через sbt run можно увидеть что-то вроде этого:
Чтобы выключить сервер, надо нажать Ctrl+C. Но вот незадача! По этой команде не только выключилось приложение, но и закрылась консоль sbt. К счастью, в project/plugins.sbt сразу подключен плагин, позволяющий этого избежать. Снова заходим в консоль, но вводим уже не run, а reStart. При необходимости выключить сервер просто вводим reStop. Теперь не придётся перезапускать консоль по нескольку раз в день.
Кроме этого плагина в комплекте с фреймворком идёт ещё несколько полезных инструментов: библиотека для продвинутого функционального программирования cats, реактивные стримы для скалы fs2, библиотека cats-effect для чистой обработки сайд-эффектов, circe для работы с JSON. И два плагина к компилятору: великолепный better-monadic-for, оптимизирующий трансляцию синтаксического сахара для for -выражений, и kind-projector, который нам не понадобится (но про него стоит почитать).
Кроме всей этой радости я хочу добавить автоматическое форматирование кода. Для этого в project/plugins.sbt прописываю строчку addSbtPlugin("com.geirsson" % "sbt-scalafmt" % "1.5.1") , в корень проекта кидаю конфиг, а в build.sbt пишу scalafmtOnCompile := true. Теперь мой код будет форматироваться при каждой компиляции (прямо как в голанге, да?). Кроме того, в опции компилятора я добавил флаг "-Xfatal-warnings", который все WARN превращает в ERROR. Просто, чтобы жизнь мёдом не казалась :)
Теперь удаляем из src/main/scala весь код, который создан по дефолту, и можно начинать программировать.
Структура проекта
Для минимального работающего приложения нужны два компонента: обработчики путей HTTP запросов и точка входа с инициализацией сервера. Для начала опишем роуты в отдельном классе (src/main/scala/scalaphashdemo/PHashService):
package scalaphashdemo
import cats.effect.Sync
import org.http4s.dsl.Http4sDsl
import org.http4s.HttpRoutes
import org.log4s.{getLogger, Logger}
class PHashService[F[_]: Sync]() extends Http4sDsl[F] {
private val logger: Logger = getLogger
val routes: HttpRoutes[F] = HttpRoutes.of[F] {
case GET -> Root => Ok("Hello")
}
}Первое, что бросается в глаза ― это F[_]. Большинство фреймворков намертво зашивают в своё апи scala.concurrent.Future для обработки асинхронных событий. В отличие от них, http4s спроектирован для написания максимально полиморфного кода. Любители tagless final порадуются :)
Если вкратце, F[_] ― это произвольный класс, хранящий значение в своём контексте. Это может быть Option[_], List[_], Future[_], и прочие классы с одним обобщённым параметром. Через запись F[_]: Sync мы накладываем на F ограничение, гласящее, что вместо него можно подставить только монады, умеющие откладывать выполнение побочных эффектов. Например, cats.effect.IO.
Звучит достаточно сложно, но на самом деле мы просто описываем минимально необходимый нам интерфейс, через который мы будем работать с асинхронными действиями и побочными эффектами. Само собой, получившаяся программа будет чистой и не будет нарушать ссылочную целостность.
Теперь перейдём к точке входа (src/main/scala/scalaphashdemo/PHashServer.scala):
package scalaphashdemo
import cats.effect.{ExitCode, IO, IOApp}
import org.http4s.server.blaze.BlazeServerBuilder
import org.http4s.dsl.io.http4sKleisliResponseSyntax
object PHashServer extends IOApp {
def run(args: List[String]): IO[ExitCode] =
BlazeServerBuilder[IO]
.bindHttp(8080, "localhost")
.withHttpApp(new PHashService[IO]().routes.orNotFound)
.serve
.compile
.drain
.map(_ => ExitCode.Success)
}Тут мы создаём наш класс и подставляем вместо абстрактного F уже конкретную реализацию ― IO. В свою очередь наследование объекта от IOApp означает, что при запуске приложения вызовется функция run.
Вопрос о практической целесообразности использования F[_] вместо IO или, например, Future напрямую я оставлю за скобками, потому что он выходит за рамки этой заметки. Остановлюсь только для нескольких утверждений:
- Основная цель использования
F[_]― разделение интерфейса и реализации; - При этом интерфейс подбирается минимально необходимый для выполнения задачи;
- Если предыдущие два тезиса не имеют для вас ценности, ничего не мешает намертво зашить в свой код
IO(val routes: HttpRoutes[IO] = HttpRoutes.of[IO] { ... }).
Теперь вернёмся к практике. Естественно, я хочу отдавать клиенту не строку, а нормальную html-страничку. При этом я не хочу делать SPA на веб-сокетах, да и вообще не хочу писать клиентский js. Поэтому мне нужен шаблонизатор html, который будет генерировать странички с данными, вычисляемыми на сервере. Из Play фреймворка в свободное плавание отпочковался шаблонизатор twirl, им я и воспользуюсь.
Чтобы подключить шаблонизатор, надо выполнить следующие шаги:
- В
build.sbtдобавить зависимость"org.http4s" %% "http4s-twirl" % Http4sVersion; - В
project/plugins.sbtподключить плагинaddSbtPlugin("com.typesafe.sbt" % "sbt-twirl" % "1.3.15"); - Создать директорию
src/main/twirl/scalaphashdemo(важно, что послеsrc/main/twirlидёт структура директорий, аналогичная той, что директорииscala!) c файломindex.scala.html; - Собрать проект через
sbt compile; - Добавить код, сгенерированный шаблонизатором, в индексацию Intellij IDEA, чтобы она лишний раз не краснила. Для этого в Project Structure находим файлы twirl в директории target и помечаем их, как исходники.
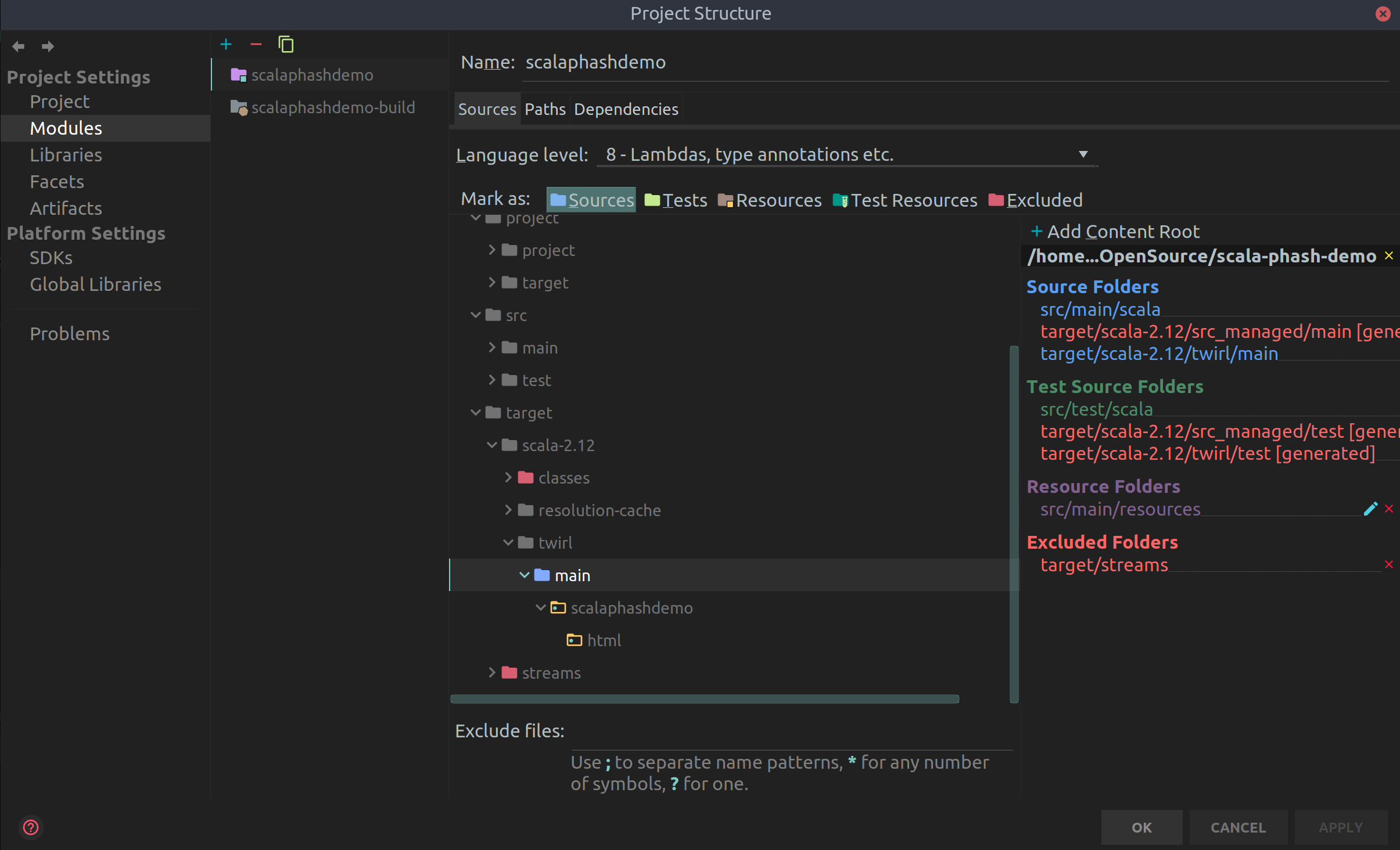
Теперь изменяем роуты, так, чтобы они отдавали свеженаписанный html. Заодно добавим отдачу произвольной статики из директории src/main/resources/static:
val routes: HttpRoutes[F] = HttpRoutes.of[F] {
case GET -> Root => Ok(html.index())
case request @ GET -> Root / "style.css" =>
StaticFile.fromResource("/static/style.css", ioEC, Some(request)).getOrElseF(NotFound())
}При чтении ресурсов фреймворк намекает программисту, что файловое I/O ― достаточно дорогая блокирующая операция. И лучше не забивать ею основной пул потоков приложения. Поэтому я передаю в функцию fromResource отдельный ExecutionContext для блокирующих операций:
val ioEC = ExecutionContext.fromExecutorService(Executors.newCachedThreadPool())Реализация демки
То, что написано дальше ― наиболее примечательные моменты из разработки моего приложения. Если вы вдруг наткнулись на эту заметку в поиске русскоязычного гайда по http4s, можно перейти сразу к заключению, потому что в этой секции будет в основном проблематика именно моей задачи.
Для получения полной картины происходящего рекомендуется читать этот раздел вместе с полными исходниками на гитхабе.
Сперва надо принять multipart POST запрос с двумя jpg файлами. Для извлечения изображений из запроса понадобилось дописать в PHashService две функции:
private def deserializeImages(multipart: Multipart[F]): F[(BufferedImage, BufferedImage)] =
multipart.parts.toList
.filter(_.headers.exists(_ == `Content-Type`(MediaType.image.jpeg)))
.traverse(parseRequestPart)
.flatMap {
case image1 :: image2 :: Nil => E.pure(image1 -> image2)
case _ => E.raiseError(InvalidImagesException)
}
private def parseRequestPart(part: Part[F]): F[BufferedImage] =
part.body
.through(toInputStream)
.evalMap(imageBytesStream => cs.evalOn(ioEC)(E.delay(ImageIO.read(imageBytesStream))))
.compile
.toList
.map(_.head)В функции parseRequestPart происходит стриминговая конвертация файла из тела запроса в объект BufferedImage из стандартной библиотеки Java. Чтобы конвертация работала эффективно, была подключена библиотечка fs2-io ради функции toInputStream, которая повысила производительность в 20 раз по сравнению с наивной реализацией, конвертирующий стрим в массив байт, и уже из него строящая объект изображения. Из-за этой функции пришлось усилить требование на F[_] до ConcurrentEffect.
Конструкция cs.evalOn(ioEC)(E.delay(ImageIO.read(imageBytesStream))) создаёт конструирует изображения на отдельном пуле потоков, чтобы не забивать основной. В переменной cs лежит ContextShift ― инструмент для переноса вычислений на другие контексты из cats-effect.
Вычисление хэшей изображений тоже долгая блокирующая операция, которую хочется распараллелить.
import cats.syntax.all._
def computeHashes[F[_], G[_]](
image1: BufferedImage,
image2: BufferedImage
)(implicit S: Sync[F], P: Parallel[F, G]): F[ImagesComparisonResult] =
(
S.delay(PHash.dctHash(image1)).rethrow,
S.delay(PHash.marrHash(image1)).rethrow,
S.delay(PHash.radialHash(image1)).rethrow,
S.delay(PHash.dctHash(image2)).rethrow,
S.delay(PHash.marrHash(image2)).rethrow,
S.delay(PHash.radialHash(image2)).rethrow
).parMapN(compareHashes).rethrowС использованием scala.concurrent.Future здесь было бы определённо больше кода. Дополнительный тип G[_] был добавлен из-за тайпкласса Parallel. При исполнении функции в неё подставляются IO вместо F и IO.Par вместо G. Метод rethrow играет важную роль: все функции расчёта хэшей возвращают Either[Throwable, Double], а rethrow в случае ошибки прокинет её сразу в F[_], чтобы избавиться от лишней вложенности. При вызове функции я исполняю её тоже на отдельном пуле при помоще evalOn.
К слову о пулах потоков. Для файлового I/O я использую CachedThreadPool, который по мере необходимости создаёт новые потоки, но при этом умеет переиспользовать старые.
А для вычислений хэшей используется FixedThreadPool с максимальным числом потоков, равному максимальному числу одновременных блокирующих операций для пары изображений. На самом деле параллелизм всё равно упрётся в количество ядер процессора, но вдруг у меня когда-нибудь будет VPS с восьмиядерным процессором :)
val computationEC = ExecutionContext.fromExecutorService(Executors.newFixedThreadPool(6))В конце-концов всё это лепится в красивое for-выражение
for {
(originImage1, originImage2) <- deserializeImages(multipart)
(image1, image2) <- reduceImages(originImage1, originImage2)
result <- cs.evalOn(computationEC)(computeHashes(image1, image2))
html <- Ok(html.index(html.resultblock(result)))
} yield htmlНапоминаю, что на гитхабе можно посмотреть полные исходники.
Заключение
Фреймворк определённо мне понравился минималистичностью, легковесностью и ориентированностью на функциональное программирование. Лепить на нём маленькие проекты ― одно удовольствие. Другое дело, что для больших проектов с высокой нагрузкой и громоздкими требованиями к API он может не подойти из-за низкой конфигурируемости и пока ещё незрелости. Для крупных проектов Akka HTTP пока что выглядит более привлекательно.
Это не значит, что http4s нельзя тащить в продакшн. Ничего не мешает использовать его для написания микросервисов с небольшим REST апи.
Важный недостаток http4s ― это нестабильность его внутреннего апи. Текущая версия на момент написания заметки 0.19, и она порядочно отличается от 0.18. Обновлять большую кодовую базу будет проблематично. Вселяет надежду только то, что разработчики находятся на пути к 1.0. А пока настоятельно рекомендую использовать самые свежие версии http4s, чтобы получить последние версии библиотек, от которых он зависит. Версия 0.18, например, тащит за собой совсем старый cats-effect.